
Neste artigo vamos explicar de forma simplificada o HDFS (Hadoop Distributed File System), tecnologia que dá suporte a muitas estratégias de gestão de dados analíticos que impactam diretamente na elevação dos níveis de maturidade analítica.
Deter um conhecimento básico deste conceito é fundamental para gestores interessados em adotar uma cultura e plataforma de dados escalável e profissionais com foco na área de engenharia de dados.
O que é o HDFS?
O HDFS é um sistema de arquivos distribuídos projetado para permitir que grandes quantidades de dados sejam armazenadas de maneira acessível em clusters de computadores. Ele foi criado para permitir que empresas processassem grandes quantidades de dados de maneira rápida e eficiente, o que é essencial em um mundo cada vez mais dependente de dados.
É importante não confundir o Hadoop, ou ecossistema Apache Hadoop, com o HDFS, que é a tecnologia do particionamento dos discos onde os dados estarão armazenados fisicamente utilizando uma estratégia de computação distribuída (várias máquinas).
O Hadoop, por outro lado, é o framework (Stack Tecnológico) de processamento de dados que utiliza, entre outras ferramentas, o HDFS para armazenar e processar grandes quantidades de dados de maneira eficiente.
Atualmente, o conhecimento sobre HDFS é um dos requisitos mais importantes para profissionais da área de computação e TI interessados em infraestrutura de grandes bases de dados.
Por que o HDFS foi criado?
A solução técnica do HDFS surgiu para atender problemas de armazenamento de dados. Estes problemas começaram a se tornar evidentes a partir dos anos 90 com o rápido crescimento de dados gerados por computadores atuando em rede e, mais recentemente, dispositivos móveis de internet das coisas (IoT).
Um ponto importante é que nesta evolução os dados cresceram apenas em quantidade como também em termos de variedade (Entendendo as diferentes naturezas e tipos de dados). Em outro artigo (Dos dados à inovação com Analytics) mostramos como se dá esta evolução no crescimento de dados e tecnologias de apoio desde a captura do dado até as análises avançadas para apoio ao conceito de indústria 4.0.
Neste contexto de grande quantidade e variedade de dados que a solução tecnológica HDFS foi gerada, fazendo com que ele fosse projetado para ser tolerante a falhas (por funcionar em rede) e para trabalhar com dados não estruturados de maneira eficiente.
O fato do HDFS ter sido desenvolvido para operar em rede o tornou, além de seguro, escalável, permitindo que novos computadores possam ser agregados ao cluster e, assim, chegar a quantidade de armazenamento muito superior e de fácil acesso quando comparados com tecnologias da época.
Em termos de escala, costuma-se utilizar o framework Hadoop e o HDFS em conjuntos de dados partindo de 100GB, podendo chegar até mesmo aos Petabytes (1 Petabyte ≅ 1 milhão de Gigabytes).
Como é estruturada a hierarquia HDFS?
O HDFS (cluster), como o “distribuído” no seu próprio nome já diz, é composto por várias máquinas que são chamadas de “nodos”. Esses nodos podem ser basicamente de 2 tipos:
Nodos de nomes (nodos de meta dados)
Os nodos de nome, ou Namenodes, são os responsáveis por manter o mapeamento dos arquivos para os nodos de armazenamento, ou Datanodes. Na prática, eles mantêm uma lista dos blocos em que cada arquivo foi dividido e para quais Datanodes eles foram enviados para serem armazenados.
Quando um usuário quer obter uma informação ou até mesmo escrever um novo arquivo no HDFS, ele envia uma solicitação ao Namenode, que por sua vez encaminha essa solicitação diretamente ao Datanode correspondente.
Nodos de dados (comumente também chamados de nodos de armazenamento)
Os nodos de dados, ou Datanodes em inglês, guardam os dados em si. No entanto, eles o fazem de forma particionada, armazenando tudo em blocos de mesmo tamanho (normalmente 128MB), após serem divididos e distribuídos.
Cluster HDFS
Esse conjunto de máquinas/nodos é chamado de cluster HDFS, e é justamente o responsável por receber e particionar os arquivos em blocos e, em seguida, distribuir esses pedaços pelos Datanodes, ao mesmo tempo que armazena essas localizações no Namenode.
Outra função muito importante do cluster é ser tolerante a falhas, e por esse motivo sempre há cópias de cada bloco espalhadas pelos Datanodes para caso de falha em um dos servidores. Esse número de cópias é determinado pelo “fator de replicação” do cluster.
Apesar de estarmos falando em arquivos aqui, o HDFS consegue armazenar uma grande variedade de tipos de dados de forma inteligente e particionada, como tabelas relacionais, coleções de dados não relacionais, arquivos de fato, entre outros.
Como funciona o método de armazenamento HDFS?
Em uma aplicação centralizada, normalmente os dados são trazidos até a aplicação para que sejam processados e consumidos. Já no HDFS, o conceito é completamente reinventado, e podemos dizer que levamos a aplicação até próximo de onde os dados estão fisicamente guardados.
Como o HDFS consiste, basicamente, em dados armazenados de forma distribuída, conseguimos utilizar esse fato como vantagem para obtermos grandes velocidades através do processamento acontecendo paralelamente em vários pontos.
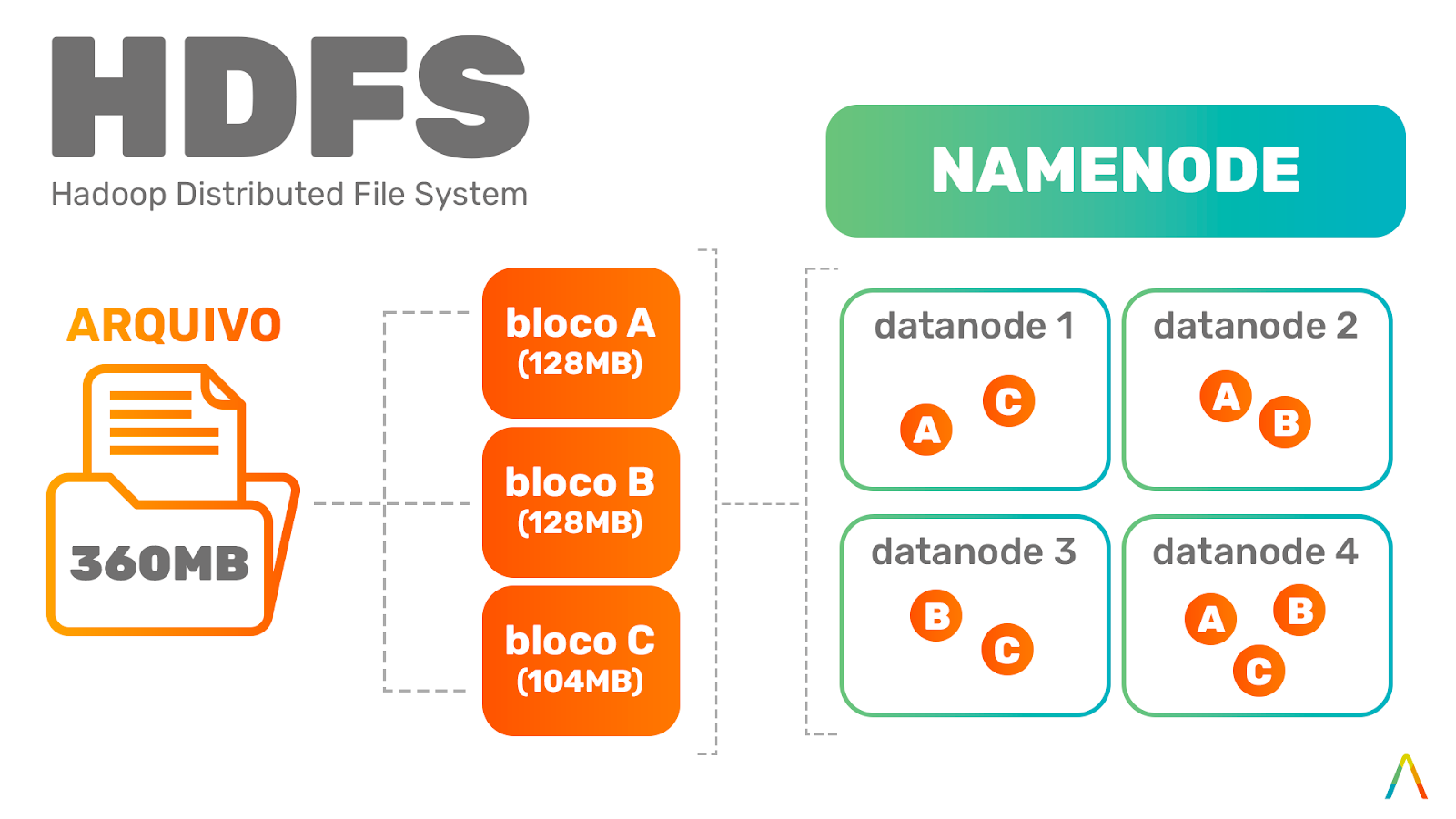
Na figura a seguir, um exemplo ilustrativo de como o cluster HDFS iria armazenar um arquivo de 360MB de forma distribuída pelos nodos:
- Primeiramente iria particionar o arquivo em blocos de, no máximo, 128MB (repare que o último bloco ficou com 104MB).
- Em seguida, o cluster distribui o primeiro bloco e suas cópias (no nosso caso aqui, 3 cópias ao total) pelos 4 nodos, de forma aleatória, de acordo com sua política de balanceamento de armazenamento.
- O processo é repetido para cada um dos blocos até que todo o arquivo tenha sido processado.
- O Namenode, nesse momento, contém a localização de todos os blocos (e suas cópias) do arquivo de entrada, o que permite que possamos executar operações em paralelo (ou seja, simultâneas) em cada um dos nodos quando estivermos querendo consultar ou computar dados desse arquivo no futuro.
Impacto da tecnologia nos negócios
O HDFS tem um grande impacto nos negócios, pois é uma tecnologia que permite que empresas desenvolvam “Data Lakes“ para inicialmente preservar seus dados de forma segura e eficiente ao longo do tempo.
Em um segundo momento do desenvolvimento da cultura e base tecnológica do Data Lake, também é possível agregar informações externas e permitir que a empresa elabore pesquisas estruturadas utilizando conhecimento de negócio, ciência de dados e inteligência artificial para alavancar a descoberta de padrões dentro das operações.
Os insights gerados a partir de dados bem armazenados e organizados são valiosos para uma tomada de decisão mais assertiva, o que pode ter um impacto positivo nas operações e nos resultados das empresas.
Esta tecnologia, que vem servindo de suporte ao ecossistema Hadoop, tem um impacto considerável na capacidade das empresas de integrar informações de vários setores da empresa e torná-las acessíveis em uma estratégia de democratização da informação de gestão, impactando diretamente nos níveis de maturidade e governança de dados.
Ele é amplamente utilizado para aplicações de análise de dados, incluindo a detecção de tendências, outliers, análises preditivas e de cenarização tais como de previsões de demanda (guia completo sobre previsão de demanda). Porém é importante ressaltar que, o HDFS precisa ser abastecido com conjunto de dados, ou datasets, de forma planejada para que as análises tenham algum valor estratégico (6 recomendações para projetos de Data Lakes).
Principais empresas que utilizam HDFS
Algumas das principais empresas que utilizam o Hadoop Distributed File System em sua infraestrutura são:
- A Amazon utiliza o HDFS para armazenar e processar grandes quantidades de dados de seus sites de e-commerce e de seus serviços de nuvem.
- O Facebook utiliza HDFS para processar e armazenar grandes quantidades de dados gerados pelos usuários do site, incluindo publicações, curtidas e comentários.
- A Yahoo foi uma das primeiras empresas a utilizar oHdfs em larga escala, e hoje o utiliza para processar e armazenar grandes quantidades de dados gerados por seus usuários, incluindo pesquisas na web, e-mails e outros dados de uso.
- O eBay utiliza o HDFS para processar e analisar grandes quantidades de dados gerados pelos usuários do site, incluindo transações de compra e venda.
- A Netflix utiliza o Hadoop para processar e armazenar grandes quantidades de dados de uso dos usuários, incluindo dados de streaming de vídeo.
Conclusões e recomendações sobre HDFS
Neste artigo, explicamos o que é a tecnologia HDFS, apresentamos algumas razões para sua criação, incluindo um exemplo de como funciona o armazenamento físico de um arquivo nesta modalidade de partição distribuída em rede e como isso pode impactar a operação das empresas, sendo o engenheiro de dados o profissional responsável pela definição da arquitetura, implantação e manutenção dos clusters.
Em resumo, o HDFS é uma forma inteligente de armazenar e processar grandes quantidades e variedades de dados em rede. Os computadores que utilizam o HDFS são conhecidos como nós ou nodos e são conectados entre si, formando clusters capazes de realizar armazenamento/processamento em grande escala de forma paralela e distribuída.
O HDFS é amplamente utilizado em aplicativos de análise de big data, o que o torna essencial para muitas empresas que dependem de um grande volume de dados para tomar decisões estratégicas.
Devido à complexidade das atividades de estruturação de projetos de dados em larga escala, é importante avaliar os fornecedores deste tipo de serviço técnico (Como escolher o melhor fornecedor de mão de obra na área de dados?).
Em futuras publicações, falaremos das tecnologias que foram desenvolvidas para acessar e manipular as informações dentro dos clusters HDFS.
Quem é a Aquarela Analytics?
A Aquarela Analytics é vencedora do Prêmio CNI de Inovação e referência nacional na aplicação de Inteligência Artificial Corporativa na indústria e em grandes empresas. Por meio da plataforma Vorteris, da metodologia DCM e o Canvas Analítico (Download e-book gratuito), atende clientes importantes, como: Embraer (aeroespacial), Scania, Mercedes-Benz, Grupo Randon (automotivo), SolarBR Coca-Cola (varejo alimentício), Hospital das Clínicas (saúde), NTS-Brasil (óleo e gás), Auren, SPIC Brasil (energia), Telefônica Vivo (telecomunicações), dentre outros.
Acompanhe os novos conteúdos da Aquarela Analytics no Linkedin e assinando a nossa Newsletter mensal!
Autores

Fundador e Diretor Comercial da Aquarela, Mestre em Business Information Technology com especialização em logística – Universiteit Twente – Holanda. Escritor e palestrante na área de Ciência e Governança de Dados para indústria e serviços 4.0.

Pai da Rafaela e da Roberta 👧 👶, CTO na Aquarela Analytics, Palestrante, Dev, Músico e Apaixonado por Música

Ph.D. em Ciência da Computação pela Sapienza Università di Roma (Itália). Doutor em Engenharia e Gestão do Conhecimento pela UFSC. Mestre em Engenharia Elétrica – ênfase em Inteligência Artificial. Especialista em Redes de Computadores e Aplicações para Web, Especialista em Metodologias e Gestão para EaD, Especialista em Docência no Ensino Superior e Bacharel em informática.
Possui experiência acadêmica como Professor, Coordenador, Palestrante e é Avaliador ad hoc do Ministério da Educação (INEP) bem como da Secretaria de Educação Profissional e Tecnológica (MEC) e do Conselho Estadual de Educação (SC).
Nas suas atividades profissionais, atua com de projetos nas áreas de: Ciência de Dados, Inteligência de Negócios, Posicionamento Estratégico, Empreendedorismo Digital e Inovação. Atua como Consultor na área de Projetos para Inovação e Soluções Computacionais Inteligentes utilizando Data Science e Inteligência Artificial.







